Methodology#
The aim of investigating the mean-squared displacements as a function of timestep is to fit a straight line and therefore obtain a estimate of the infinite timescale diffusion coefficient. This might seem like a straight forward concept, however, for a real simulation, with a limited number of atoms and simulation length, the observed value of the diffusion coefficient will vary upon repetition of a given simulation. kinisi is a Python library that is capable of:
Accurately estimating the infinite timescale diffusion coefficient from a single simulation
Quantifying the variance in the diffusion coefficient that would be observed on repetition of the simulation
In order to achieve this, it is neccessary to build up a complete picture of the observed diffusion from the simulation and use this information to apply the approach with the highest statistical efficiency to estimate the diffusion coefficient. The different approach that can be taken to estimate this are shown in the schematic below, which we will work through below.
Note, that this is not aimed to show how kinisi should be run but rather to outline the methodology that kinisi uses. Examples of how to run kinisi from the API can be found in the notebooks.
A schematic of the process of diffusion coefficient determination, where the process used in kinisi is identified with the pink box.
Finding the mean-squared displacement#
Consider first the displacements that we calculate from an atomic simulation. We have performed a simulation of lithium lanthanum zirconium oxide (LLZO) to use as an example, we will consider initially the displacements, \(\mathbf{x}\), that occur in 5 ps of simulation time.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
from scipy.optimize import minimize
from emcee import EnsembleSampler
from corner import corner
[2]:
displacements = np.load('_static/displacements.npz')['disp']
print('Displacements shape', displacements.shape)
Displacements shape (192, 91, 3)
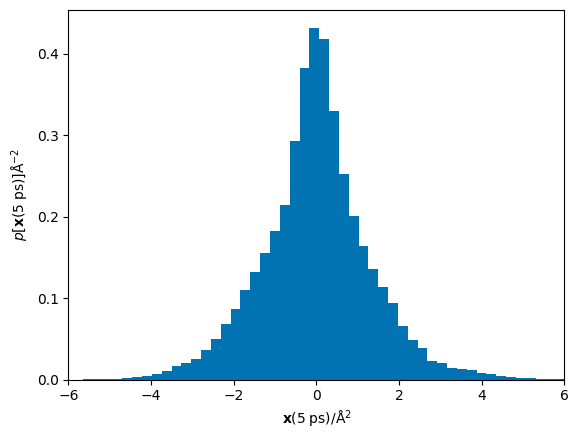
We can see that for this timestep, the displacements array has a shape of (192, 6, 3) this means that there are 192 atoms, each observed 6 times (i.e. in the whole simulation there 6 non-overlapping times that 2.1 ps of simulation is present), for 3 dimensions. Let us now visualise the probability distribution for the displacements.
[3]:
plt.hist(displacements.flatten(), bins=50,
density=True, color='#0173B2')
plt.xlabel(r'$\mathbf{x}(5\;\mathrm{ps})$/Å')
plt.ylabel(r'$p[\mathbf{x}(5\;\mathrm{ps})]$Å$^{-1}$')
plt.xlim(-6, 6)
plt.show()
The ordinate axis in the fitting of the Einstein equation is the mean of the squared displacements, \(\mathbf{r}^2\), therefore we must square these displacements and determine the total displacement over all dimensions.
[4]:
sq_displacements = np.sum(displacements ** 2,
axis=2).flatten()
plt.hist(sq_displacements, bins=50,
density=True, color='#0173B2')
plt.xlabel(r'$\mathbf{s}^2$/Å$^2$')
plt.ylabel(r'$p(\mathbf{s}^2)$/Å$^{-2}$')
plt.show()
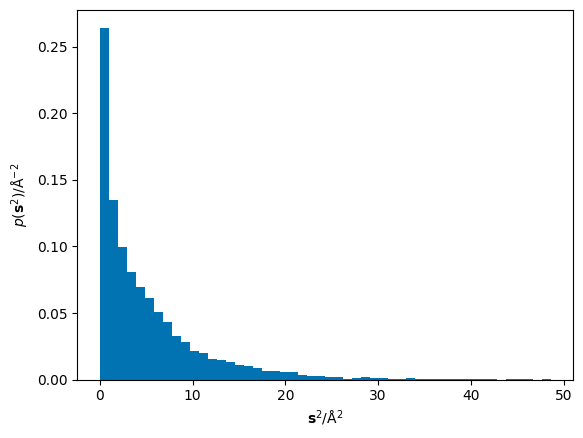
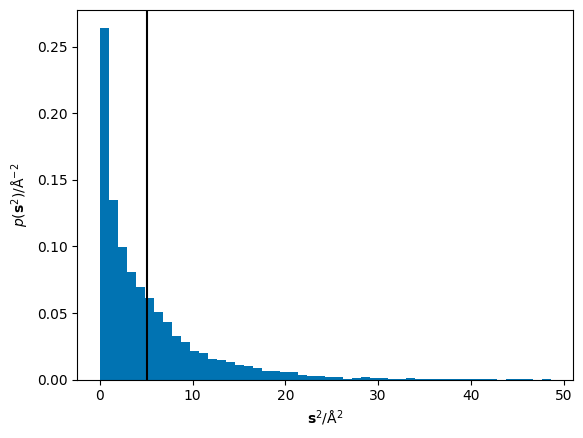
The mean of these squared displacements, \(\langle\mathbf{r}^2\rangle\), can be found as the numerical mean. Below, the mean is shown as a black vertical line over the histogram of the squared displacements.
[5]:
msd = np.mean(sq_displacements)
print(f'MSD = {msd:.3f} Å$^2$')
plt.hist(sq_displacements, bins=50,
density=True, color='#0173B2')
plt.axvline(msd, color='k')
plt.xlabel(r'$\mathbf{s}^2$/Å$^2$')
plt.ylabel(r'$p(\mathbf{s}^2)$/Å$^{-2}$')
plt.show()
MSD = 5.111 Å$^2$
Therefore, if we perform this operation at a series of different timesteps (the x-axis in the diffusion relation), we can populate the y-axis for our dataset. This is shown for the LLZO material below (note that throughout this description we focus on data in the diffusive regime alone).
[6]:
dt, msd = np.loadtxt('_static/msd.txt')
plt.plot(dt, msd, c='#0173B2')
plt.ylabel('MSD/Å$^2$')
plt.xlabel(r'$\Delta t$/ps')
plt.xlim(0, None)
plt.ylim(0, None)
plt.show()
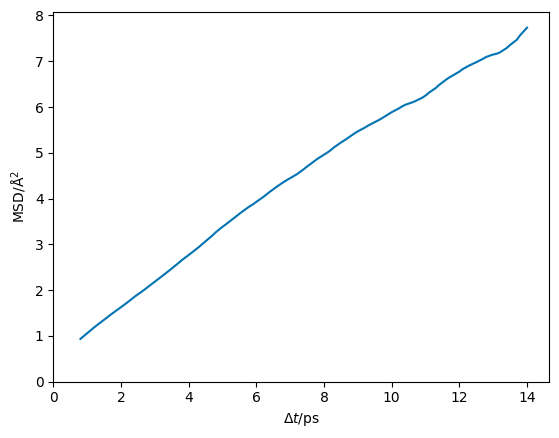
The first thing we notice is that this data has no uncertainty associated with it. Given that this simulation is of a finite size, this is impossible. Consider, if we run another independent simulation of the same system, we will probably get different MSD plots.
Finding the uncertainty in the mean-squared displacement#
The variance for all observed sqaured displacements can be found. However, this will underestimate the variance as it makes use of a large number of overlapping trajectories. Therefore, the variance should be rescaled by the number of non-overlapping trajectories. For 5 ps of simulation, there is only two non-overlapping trajectories per atom, so the number of samples in the resampling should be \(2 \times N_{\mathrm{atoms}}\).
[7]:
var = np.var(sq_displacements, ddof=1) / 384
print(f'Variance = {var:.3f} Å^2')
Variance = 0.091 Å^2
From this, we can find the mean and standard deviation.
[8]:
print(rf'MSD = {np.mean(sq_displacements):.3f}+\-{np.sqrt(var):.3f} Å^2')
MSD = 5.111+\-0.302 Å^2
We have information about the distribution of the mean-squared displacement and we can visualise this for a real material below.
[9]:
dt, msd, msd_std = np.loadtxt('_static/msd_std.txt')
plt.errorbar(dt, msd, msd_std, c='#0173B2')
plt.ylabel('MSD/Å$^2$')
plt.xlabel(r'$\Delta t$/ps')
plt.xlim(0, None)
plt.ylim(0, None)
plt.show()
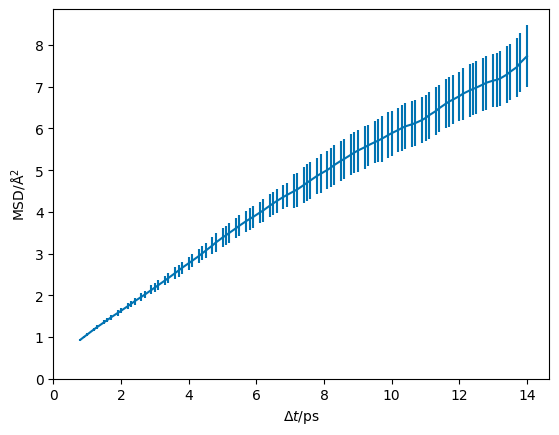
Understanding the correlation between measurements#
However, the knowledge of the distribution of mean-squared displacements does not completely describe the variance in the data set.
Thought experiment
Consider, a particle travelling on a one-dimensional random walk with a step size of 1 Å. If, after 10 steps, the particle has been displaced by 5 Å then after 11 steps the particle could only be displaced by either 4 Å or 6 Å and after 12 steps the particle could only be displaced by 3, 4, 5, 6, 7 Å.
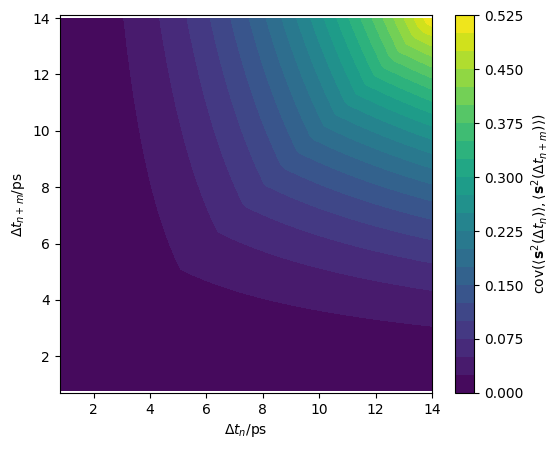
This fact results in a substantial correlation between the distributions of mean-squared displacement at different timesteps. To quantify this correlation, we have derived an approach to estimate the full covariance matrix (a description of the correlation between the timesteps). The result of this derivation is that the covariance between two timesteps, \(\mathrm{cov}_i\Big(\big\langle \mathbf{r}^2(\Delta t_n) \big\rangle, \big\langle \mathbf{r}^2(\Delta t_{n+m}) \big\rangle\Big)\), is the product of the variance at the first timestep, \(\Delta t_n\) and the ratio of maximum independent trajectories at each timestep,
This approach is extremely computationally efficient, as there is no additional sampling required to determine this estimate of the full covariance matrix. However, the noise sampled variances may lead to poorly defined covariance matrices, therefore the variances are smoothed to follow the function defined in Equation 14 of the derivation. This leads to the covariance matrix shown for our LLZO simulation in the figure below.
[10]:
data = np.load('_static/cov.npz')
cov = data['cov']
plt.subplots(figsize=(6, 4.9))
plt.contourf(*np.meshgrid(dt, dt), cov, levels=20)
plt.xlabel(r'$\Delta t_n$/ps')
plt.ylabel(r'$\Delta t_{n+m}$/ps')
plt.axis('equal')
plt.colorbar(label=r'$\mathrm{cov}' +
r'(\langle \mathbf{s}^2(\Delta t_n) \rangle, ' +
r'\langle \mathbf{s}^2(\Delta t_{n+m}) \rangle)$')
plt.show()
Modelling a multivariate normal distribution#
The determination of the variance in the mean-squared displacement and estimation of the full covariance matrix allows the mean-squared displacement to be described as a covariant multivariate normal distribution, and therefore we can define it with a scipy.stats.multivariate_normal object.
[11]:
gp = multivariate_normal(mean=msd, cov=cov, allow_singular=True)
This object, in theory, allows us to simulate potential trajectories that could be observed in our simulation were repeated. In the plot below, we compare such a simulation from the multivariate normal distribution produced from the full covariance matrix with that produced when there only the diagonal terms are defined (i.e. only the variances for each mean-squared displacement).
[12]:
gp_wls = multivariate_normal(
mean=msd, cov=np.diag(cov.diagonal()), allow_singular=True)
plt.plot(dt, gp.rvs(1).T, label='GLS', c='#0173B2')
plt.plot(dt, gp_wls.rvs(1).T, label='WLS', c='#029E73')
plt.legend()
plt.ylabel('MSD/Å$^2$')
plt.xlabel(r'$\Delta t$/ps')
plt.xlim(0, None)
plt.ylim(0, None)
plt.show()
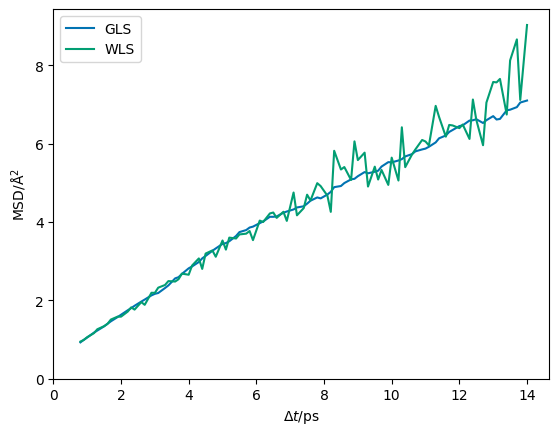
The erratic changes in the mean-squared displacement that is observed in the plot with only the variances defined are unphysical when we consider the correlation thought experiment above.
Likelihood sampling a multivariate normal distribution#
As mentioned above, this process aims to determine the diffusion coefficient and ordinate offset, and their model variance, by fitting the Einstein relation. In kinisi, we use Markov chain Monte Carlo (MCMC) posterior sampling to perform this, using the emcee package. To perform this, we define a log_posterior function, that imposes a Bayesian prior probability that the diffusion coefficient must be positive.
[13]:
def log_prior(theta):
"""
Get the log-prior uniform distribution
:param theta: Value of the gradient and intercept of the straight line.
:return: Log-prior value.
"""
if theta[0] < 0:
return -np.inf
return 0
def log_likelihood(theta):
"""
Get the log-likelihood for multivariate normal distribution.
:param theta: Value of the gradient and intercept of the straight line.
:return: Log-likelihood value.
"""
model = dt * theta[0] + theta[1]
logl = gp.logpdf(model)
return logl
def log_posterior(theta: np.ndarray) -> float:
"""
Summate the log-likelihood and log prior to produce the
log-posterior value.
:param theta: Value of the gradient and intercept of the straight line.
:return: Log-posterior value.
"""
logp = log_likelihood(theta) + log_prior(theta)
return logp
Then we can use a minimisation routine to determine maximum a posteriori values for the gradient and intercept.
[14]:
def nll(*args) -> float:
"""
General purpose negative log-posterior.
:return: Negative log-posterior
"""
return -log_posterior(*args)
max_post = minimize(nll, [1, 0]).x
[15]:
print(f'MAP: m = {max_post[0]:.3f}, c = {max_post[1]:.3f}')
MAP: m = 0.594, c = 0.461
After determining the maximum a posteriori, we can use emcee for sampling with 32 walkers for 1000 samples (with a 500 sample burn-in, which we discard in producing the flatchain).
[16]:
pos = max_post + max_post * 1e-3 * np.random.randn(32, max_post.size)
sampler = EnsembleSampler(*pos.shape, log_posterior)
sampler.run_mcmc(pos, 1000 + 500, progress=False)
flatchain = sampler.get_chain(flat=True, discard=500)
The diffusion coefficient (in units of cm2s-1) is found by dividing the gradient by 60000).
[17]:
flatchain[:, 0] /= 60000
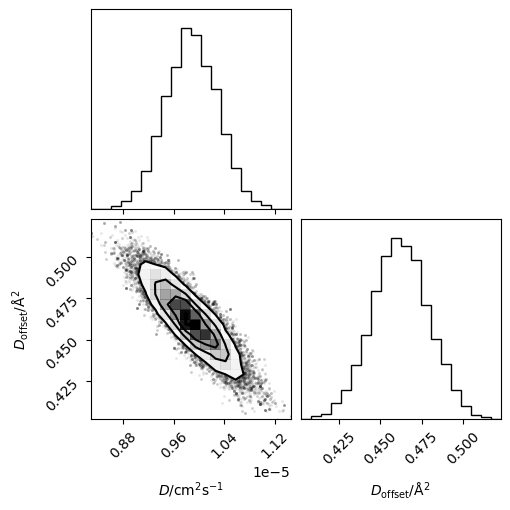
We can then visualise these samples as a corner plot.
[18]:
corner(flatchain,
labels=['$D$/cm$^2$s$^{-1}$', r'$D_{\mathrm{offset}}$/Å$^2$'])
plt.show()
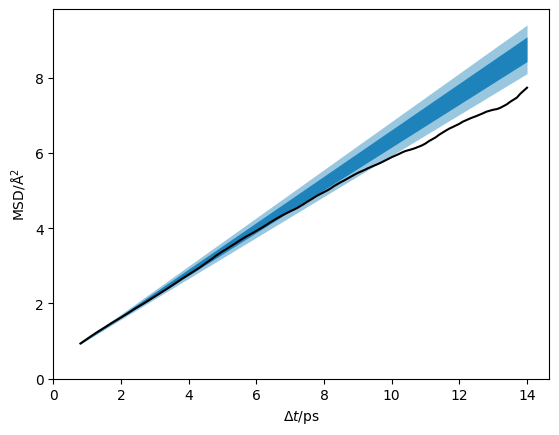
It is also possible to visualise this as a traditional mean-squared displacement plot with credible intervals of the Einstein relation values.
[19]:
credible_intervals = [[16, 84], [2.5, 97.5]]
alpha = [0.8, 0.4]
plt.plot(dt, msd, color='#000000', zorder=10)
distribution = flatchain[
:, 0] * 60000 * dt[:, np.newaxis] + flatchain[:, 1]
for i, ci in enumerate(credible_intervals):
plt.fill_between(dt,
*np.percentile(distribution, ci, axis=1),
alpha=alpha[i],
color='#0173B2',
lw=0)
plt.ylabel('MSD/Å$^2$')
plt.xlabel(r'$\Delta t$/ps')
plt.xlim(0, None)
plt.ylim(0, None)
plt.show()